强化学习笔记01-问题定义
前言
由于工作需要,近期学习一些强化学习的内容。主要的参考资料是David Silver的讲课,
边写笔记,边学习的效率比较高,所以后面会开一个系列博客,发表我的学习笔记,由于还是这个方面的菜鸡,所以肯定有些地方领悟得不够透彻,还请大家多多包涵。
学习大纲
教材分为三个部分
- The Problem, Chapter 1~3
- Elementary Solution Methods, Chapter 4~6
- Unified View, Chapter 7~11
课本推荐的阅读策略
- Chapter 1 简短看下
- Chapter 2 看到2.2
- Chapter 3 略过3.4,3.5和3.9
- Chapter 4,5,6 按顺序阅读, Chapter 6最重要
- Chapter 8 如果关注机器学习和神经网络,看这章
- Chapter 9 如果关注AI或规划,看这章
- Chapter 10 最好看
- Chapter 11 例子,可以看看
推荐阅读方法
- 由于教材,课件和授课视频同步,可以按章节阅读
- 每个章节
- 粗略读教材对应章节,大概了解相关概念
- 阅读课件,记住不清楚的概念
- 详细观看授课视频,不清楚的地方可以反复观看。
- 第二次详细阅读课件+教材
- 整理笔记,梳理整个章节的内容,还有不明白的地方google检索相关概念。
第一讲笔记
非贪心算法,牺牲当前利益,获取长远利益
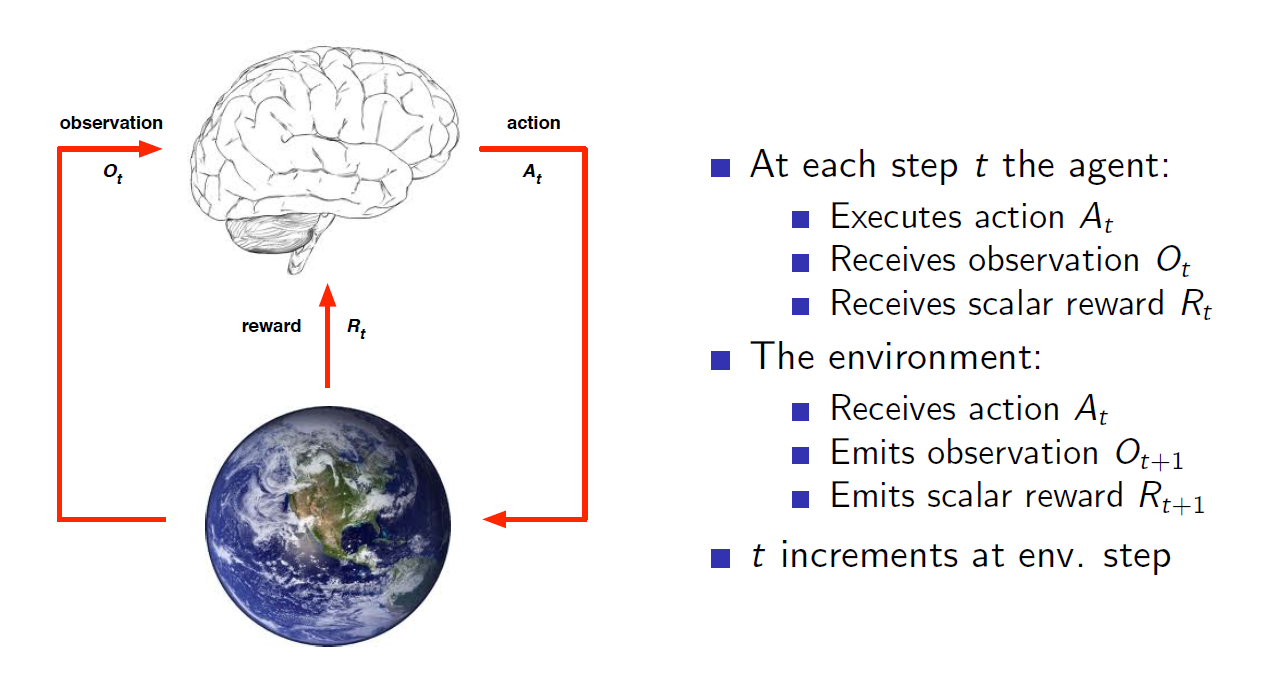
核心工作原理示意图。在每一步t,
Agent
- 执行$A_t$
- 接收$O_t$
- 获取奖励$R_t$
环境
- 接收$A_t$
- 输出观察$O_{t+1}$
- 输出奖励$R_{t+1}$
State是用于接下来该做什么的信息。比较难理解,下面的例子比较直观。
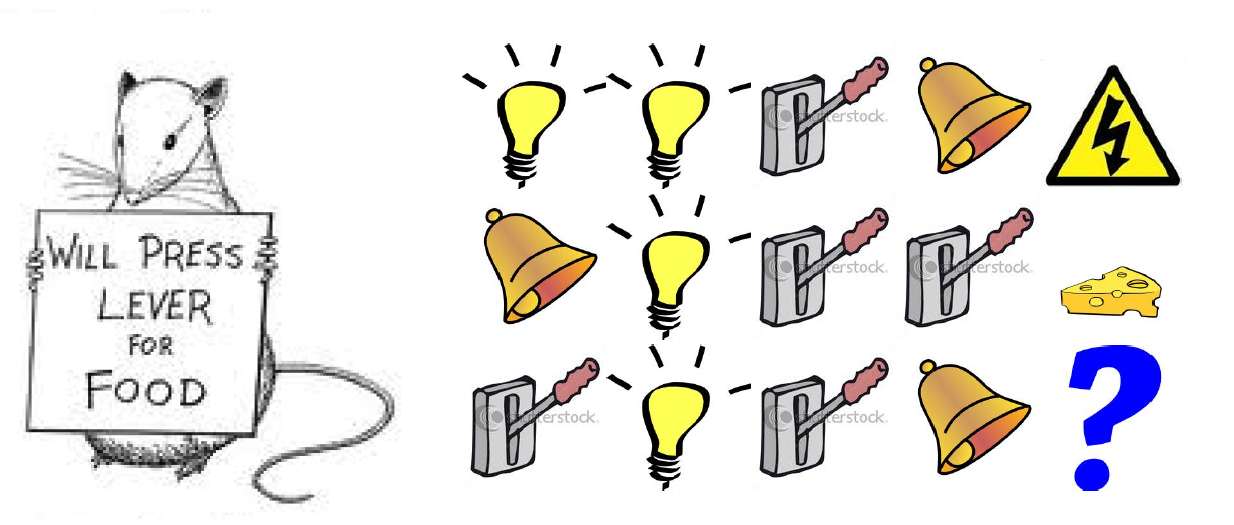
- Reward 电击或奶酪
- State 前面的序列
- Action 是否按把手
通过观察前面的历史序列,可以有两个State
- 通过观察最后是三个序列
- 通过计数亮灯次数
这两个state,可以得到不同的reward。
- Policy State到action的映射
- Value Function 未来reward的预估
- Model 预估环境下一步做什么,比如下一步状态或奖励
补充
2017/11/27, 内部分享讨论后,一些新的感悟。
状态的Markov建模
Daivd课件中提到可以用Markov的方式处理状态。一旦当前状态已知,历史数据可以抛弃。所以可以使用Markov的方式为状态转移建模。以围棋为例,每个盘面可以作为一个状态,在已知当前盘面时,下一步如何下,跟以前的历史盘面没有多大关系,只会根据当前盘面状态思考下一步或下几步。虽然根据当前$S_t$给出了$A_t$,并且已经思考了后面$A_{t+1},\cdots,A_{t+k}$的动作。但是一旦$S_{t+1}$与预期不一样,$A_{t+1},\cdots,A_{t+k}$等需要重新设定。根据环境做出变化,这也正是强化学习区别于其他学习的地方。
RL推荐系统的环境模拟
一般RL教材和资料中,使用的环境都是比较方便模拟,或者有现成的模拟环境。比如广泛使用的Grid World例子以及变种,还有一些直接使用戏作为例子。这些环境,我们都可以清楚的知道内部运行机制,从而得到完整的环境。但是,有些场景无法得到理想的环境。比如,希望用强化学习进行商品推荐,推荐系统是Agent,所有的用户组成环境。用户的信息,虽然可以得到部分,比如年龄,性别,最近购买等,但是远远不够用来模拟用户。比如用户当前的心情(是否刚和老婆吵架,儿子数学考试又不及格),周遭环境(在公交上,躺在沙发上),家庭背景(深二代,富二代),性格(理性,冲动,低调)特征等。如何解决这个问题。据说阿里和一些科研机构正在研究如何通过对用户行为建模,模拟用户个体,然后用这些用户个体组成整个环境,不过这个是前沿研究,而且需要投入大量资源,对于小团队不太适用。
一种轻量级的方法,将整个环境认为是一个分类模型,对于分类模型而言,有物品(action),有状态(用户数据),也有标签(历史购买情况),可以建模。这样,离线情况下,RL模型不断与这个分类模型交互,学到一个初始模型。当RL模型稳定后,用线上真实环境替换分类器环境,进行真实的线上强化学习。当然,初始RL模型的效果与分类模型的精度有直接关系,但是聊胜于无。最后,推荐阅读文章(2013)Playing Atari with Deep Reinforcement Learning。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!