Spark优化那些事(5)-关于job,stage,task与join优化
昨天陪老婆产检,虽然去的很早,但是人超多,闲来无事看了一本关于spark优化的小册子High Performance Spark - Early Release。终于梳理清楚了job,stage和task的关系(好惭愧)。同时看到join的几种策略,正好与我手头上的工作相关。所以总结于此,方便后面回顾。
Job,Stage和Task
一个job对应一个action(区别与transform)。比如当你需要count,写数据到hdfs,sum等。而Stage是job的更小单位,由很多trasnform组成,主要通宽依赖划分。相邻的窄依赖会划分到一个stage中,每个宽依赖是stage的第一个transform。而每个task,就是我们写的匿名函数在每个分区上的处理单元。有多少个分区,就需要少个task。task的并行化是有$executor数量\times core数量$决定的。task过多,并行化过小,就会浪费时间;反之就会浪费资源。所以设置参数是一个需要权衡的过程,原则就是在已有的资源情况下,充分利用内存和并行化。
举个例子总结Job,Stage和Task的关系
def simpleSparkProgram(rdd : RDD[Double]): Long ={
//stage1
rdd.filter(_< 1000.0)
.map(x => (x , x) )
//stage2
.groupByKey()
.map{ case(value, groups) => (groups.sum, value)}
//stage 3
.sortByKey()
.count()
}上面代码的图形化解释如下,
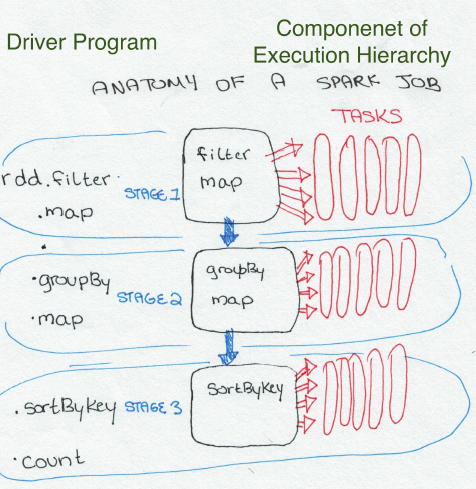
你可能问我为甚要理解这些?说来惭愧,之前对这些理解不够深刻,定位问题的效率不高。比如常见的数据倾斜。当理解了这些,如果出现了数据倾斜,可以分析job,stage和task,找到部分task输入的严重不平衡,最终定位是数据问题或计算逻辑问题。
Join的执行策略
Join优化可以说是工作中遇到的最为常见的问题,没有之一。spark当然会在这个问题上做优化,但是前提是你需要知道其工作原理。简单来说,join有三个策略。
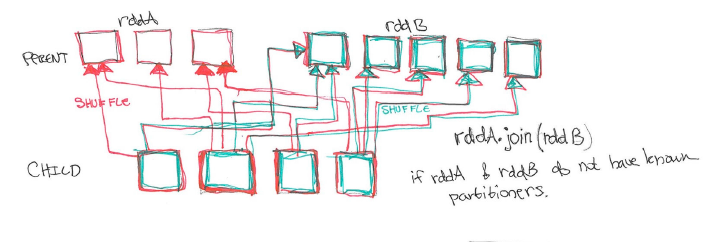
- 策略1: 两个RDD的分区都不知道,那么一起shuffle,非常消耗网络IO,效率最低。
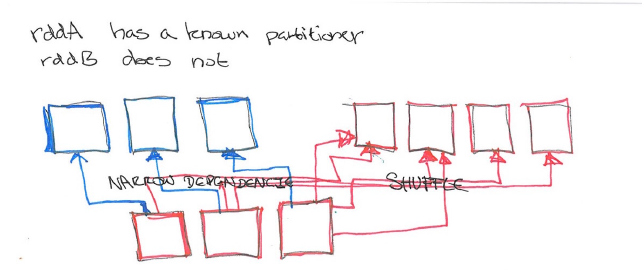
- 策略2:只知道一个RDD的分区,两一个不知道,那么已知分区的RDD只需要窄依赖,而不知分区的需要shuffle,效果较高。
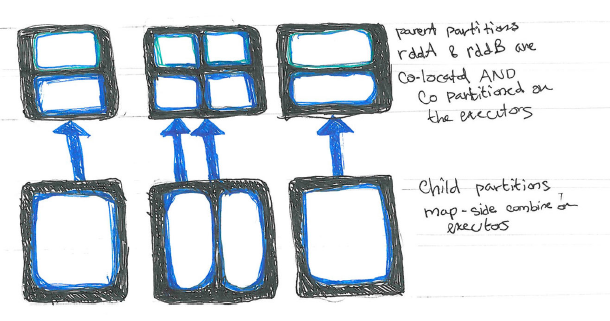
- 策略3:两个RDD的分区均已知,且相同。那么无需shuffle,只需要将对伊分区合并即可,效率最高。
所以,优化join的核心思想就是减少shuffle,统一分区策略,我常用分区策略是HashPartitioner。参考代码如下:
def joinScoresWithAddress3( scoreRDD : RDD[(Long, Double)],
addressRDD : RDD[(Long, String )]) : RDD[(Long, (Double, String))]= {
//if addressRDD has a known partitioner we should use that,
//otherwise it has a default hash parttioner, which we can reconstrut by getting the umber of
// partitions.
val addressDataPartitioner = addressRDD.partitioner match {
case (Some(p)) => p
case (None) => new HashPartitioner(addressRDD.partitions.length)
}
val bestScoreData = scoreRDD.reduceByKey(addressDataPartitioner, (x, y) => if(x > y) x else y)
bestScoreData.join(addressRDD)
}当然,如果一个RDD非常小,可以使用broadcast进行hash join。
最后,如果大家觉得High Performance Spark - Early Release有用,请购买正版。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!