强化学习笔记06-函数逼近
最近我的第一个孩子刚出生,导致学习RL的进度有点落后。今天双十一,牺牲了剁手的时间写学习笔记,弥补落后的进度。
概要简介
这一讲的主要内容是将前面提到的Q和V表用函数替代,称为Function Approximation。表格查询,本质上就是函数,输入索引号,返回对应值,只是形式比较特殊。为什么要用函数替代?因为如果表格空间太大,比如$10^{20}$,那么存储表格需要大量空间。有些问题,状态是连续的,比如直升飞机控制。这些场景都需要使用函数来计算奖励。
Function Approximation可以用监督学习来求解,可以转成回归问题。那么,我们常用的监督学习算法就可以派上用场,比如线性回归,SVM,决策树,GBDT,随机森林,kNN,DNN等等。但是,强化学习需要不断与环境变交互,作出快速调整,所以学习过程是一个迭代的过程。而前面提到的算法中,线性回归和DNN比较适合这个场景,因为它们可导 ,使用梯度递减求解,该过程是迭代的,与强化学习过程一致。DNN最近非常流行,与强化学习结合起来称为深度强化学习 。DNN+Q-Learning(+批处理)称为DQN,最著名的例子是使用DQN玩Atari游戏,直接输出入Atari游戏画面,DQN控制行为,很多游戏上都可以比人类玩家表现出色,下面是DQN在一个Atari游戏中的表现,绿色是DQN,黄色是人类玩家。

SARSA和Q-Learning中,核心算法逻辑不变,只是Q表更新换成了SGD,Q表查询换成函数预测。本节还介绍了FA在RL中的收敛性。一般在线性FA上,基本可以收敛,非线性虽然不保证收敛,但是实际效果一般还不错。如果需要在大规模上应用FA+RL,那么需要现在计算方法上有所改变。本讲最后一部分介绍了Batch的方法,简而言之就是将过往数据收集起来,然后不断抽样进行模型更新。更新后的模型,然后再同步到线上进行应用。
增量方法
值函数逼近预估
该方法主要是通过不断与环境交互,通过SGD更新值函数参数$w$,逐步求解。很显然,目标值是连续的,所以使用平方误差。$w$更新如下
\[\Delta w = \alpha(v_\pi(S))-\hat{v}(S,w))\bigtriangledown_\pi \hat{v}(S,w) \qquad (1)\]为了计算导数,需要将状态S变成特征向量,变换方法根据应用场景变化,表示方法如下
\[x(S) = \begin{pmatrix} x_1(S) \\ \vdots \\ x_n(S) \end{pmatrix}\]线性函数逼近(线性回归)是最简单,也最易于数学分析。应用到强化学习场景,值函数表示如下
\[\hat{v}(S) = x(S)^Tw = \sum_{j=1}^n x_j(S)w_j \qquad (2)\]对上面的形式求导,可参考线代随笔11-线性回归相关的向量求导,其形式为$\bigtriangledown_w \hat{v}(S,w)=x(S)$ ,将梯度代入(1),
\[\Delta w = \alpha(v_\pi(S)-\hat{v}(S,w)) x(S) \qquad (3)\](3)可以形象的理解为$Update = step \ size \times prediciton \ error \times feature \ value$。值函数表格查询其实是函数逼近的一种特殊形式,此时$w$的每个元素代表表格中的对应值。
$v_\pi(S)$的真实值是无从得知,实际中,根据不同的方法,用不同的替代方案,
- Mento-Carlo,使用$G_t$替代
- MC的目标是无偏估计,可收敛到最优
- 非线性值函数也可以确保收敛到最优解
- TD(0),使用$R_{t+1} + \gamma \hat{v}(S_{t+1},w)$替代
- TD(0)目标是有偏估计
- 无法确保收敛,但是在最优值点附近
- TD($\lambda$),使用$G_t^\lambda$替代
- TD($\lambda$)目标仍然是有偏估计,但是随$\lambda$增大,趋向于无偏估计
- 通过后向视角更新,结果与前向视角一致
值函数逼近控制
主要思路与值函数逼近类似,但是要添加动作,参数更新方法如下
\[\Delta w = \alpha(q_\pi(S,A))-\hat{q}(S,A,w))\bigtriangledown_\pi \hat{q}(S,A,w) \qquad (4)\]特征计算方法也需要考虑行为,
\[x(S,A) = \begin{pmatrix} x_1(S,A) \\ \vdots \\ x_n(S,A) \end{pmatrix}\]目标函数的处理和值函数逼近类似,这里不再重复。
收敛性
前面讲了那么多值函数预测的方法,并不是所有方法最终会收敛到最优解,结合本章所讲解的函数逼近,下面给出总结,Gradient TD就是本节提到的逼近方法,MC和TD是之前提到的方法
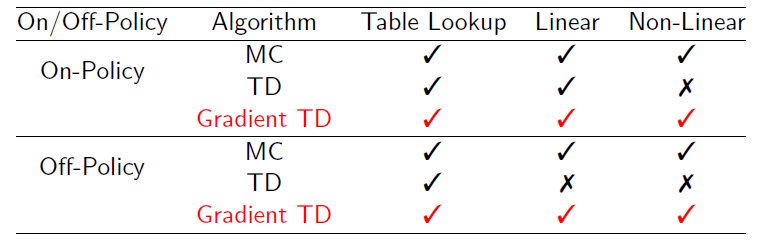
TD不跟随梯度同时是有偏估计,所以在off-policy或non-linear时会发散。Gradient TD跟随梯度,所以均不会发散。
MC-控制,SARSA,Q-learning均属于控制方法,结合本章的函数逼近,Graidient Q-learning是Q-learning的改进版本。
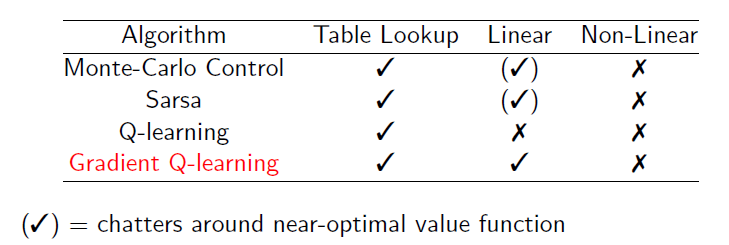
可以看到,Gradient Q-learning在线性逼近函数上仍然可以收敛。所有的方法,在非线性函数上,均无法保证收敛,因为不能确保目标函数是凸函数。
基于FA的Q-Learning和SARSA实现以及实验参考这里,使用经典的小车爬坡实验,使用线性模型拟合动作值函数,SARSA收敛明显比Q-Learning慢。
批处理方法
基本思想
前面提到的方法无法有效利用样本,每次更新模型需要与环境交互,使用一次交互数据及抛弃,历史数据无法重复使用。所以出现了批处理学习方法,高效利用最近的历史样本。有点类似mini batch GD,称为经验重放 ,收集最近发生的经验$D = { \langle s_1,v_1^\pi \rangle, \cdots, \langle s_T,v_T^\pi \rangle }$,
重复以下操作
- 抽取样本$\langle s, v^\pi \rangle \sim D$
- 使用样本更新逼近函数,$\Delta w = \alpha(v^\pi-\hat{v}(s,w))\bigtriangledown_\pi \hat{v}(s, w)$
直到收敛,得到最终$w^\pi$。
DQN
简单介绍了DQN的思想以及效果,整体上是DNN+RL,但是里面还是有一些tricks,比如fixed point(off-policy方法), experence-replay等等,更详细的内容可以参考论文(2015)Human-level control through deep reinforcement。
线性最小二乘预测
前面提到的线性最小二乘预测是在单一样本的情况下的形式。在批处理的情况下,需要引入多个样本。在最优点的情况下,其形式为
\[\Delta w = \alpha \sum_{t=1}^T x(s_t) (v_t^\pi- x(s_t)^Tw) = 0\]上面形式$w$有解析解,
\[w=\left( \sum_{t=1}^Tx(s_t)x(s_t)^T \right)^{-1}\sum_{t=1}^Tx(s_t)v_t^\pi\]如果特征数为n,矩阵求逆复杂度为$O(n^3)$,采用增量求逆,复杂度为$O(n^2)$,在n很小时,可以接受。$v_t^\pi$仍然是未知的,所以采取其他方式替代,得到变种算法
- LSMC, $v_t^\pi \approx G_t$
- LStD,$v_t^\pi \approx R_{t+1} + \gamma \hat{v}(S_{t+1},w)$
- LSTD($\lambda$),$v_t^\pi \approx G_t^\lambda$
上面三个形式均有解析解,这里略去,详细情况可以参考课件。收敛关系如下
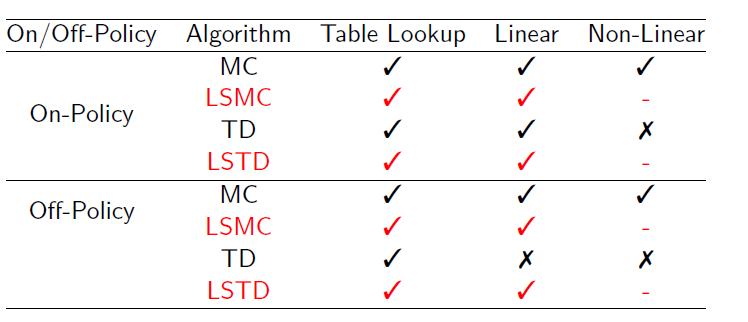
可以看到,LS系列算法均可以收敛。
线性最小二乘控制
使用GPI思想,逐步更新策略。线性逼近行为值函数$q(s,a)$。类似Q-learning,使用$\pi$策略生成样本,更新$\mu$策略。LSTDQ,相比于LSTD,多出了一个参数$\pi$,该方法的$w$也具有解析解,推导如下
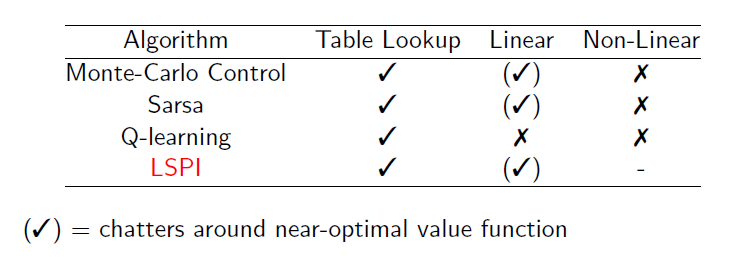
\[0=\sum_{t=1}^T\alpha \left(R_{t+1} + \lambda \hat{q}(S_{t+1}, \pi(S_{t+1}),w)-\hat{q}(S_t,A_t,w) \right) x(S_t, A_t) \\ \Rightarrow \\ w = \left( \sum_{t=1}^T x(S_t,A_t) (x(S_t,A_t)-\gamma x(S_{t+1}, \pi(S_{t+1})))^T \right)^{-1} \sum_{t=1}^Tx(S_t,A_t) R_{t+1}\]使用LSTDQ的更新方式很简单,初始化$\pi = \pi_0$,不断将$\pi$传给LSTDQ得到新的$\pi$,直到$\pi$变化很小为止,此方法称为LSPI-TD,其伪代码如下

概算法收敛效果也不错,
2017-1-8分享总结
这次分享,谈到了批处理中的技巧Experience Replay。该技巧的主要作用是降低了Variance。比如在围棋中,可能第195手与第196手,带来的收益值函数是巨大的,但是在状态空间上,他们的差异基本上可以忽略不计。所以,如果直接就这样学习,那么target的variance巨大,肯定无法得到较好的拟合。不过,通过在之前的Experience中随机抽取,可以规避这个问题。实验证明,DQN在Atari游戏上的效果有很大提升。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!