Does our video understanding model evolve?
Since the 4G era, the network bandwidth has increased significantly. As a result, it makes the short video more and more popular worldwide, primarily driven by Tiktok. Meanwhile, more and more advertisements appear in the form of videos. According to statistics, nearly more than 80% of ads around the global markets are videos.
As the trend goes on, it’s valuable to analyze these videos efficiently and effectively to produce insights so that marketing teams can acquire more new users with the same budgets. We have been working on this problem since Dec. 2021, and our solution has been evolving. So, I will present the main idea behind the scene as a memo.
Our solution has gone through two significant changes, so I use two sections to present them.
State 1
From Dec. 2020 to Jun. 2021, we thought of this problem as an extension of image classification. We trained many CNN-based models to classify different topics, such as terrain, weapons, carriers, etc. We sampled frames from each video and used these models to obtain the tags for each frame. Then, we use a rule-based method to aggregate the tags to get higher-level tags.
The method works, but not elegantly, and even a bit of uglily. First, we should maintain many CNN-based models, which require many resources to maintain. Then, we did not leverage the background music, roles’ speeches, and text in the video, which means we wasted a lot of information.
In April, TAAC(Tencent Advertisement Algorithm Competition) 2021 began. The task is to deconstruct the advertisement, which first segments a video temporally and then tags each part. As a result, we can get the structure of a video, with which it can be straightforward to make more profound insights. All of it is what we purse, so we participated in the competition. After two months of hard work, we had learned and invested so much in the competition. Our dedication has finally paid off that our team won the internal 2nd prize.
State 2
From Jul. 2021 to present, our team began to refactor our first stage model with the approach learned from the competition. We treat it as a multi-modal problem, which uses deep learning models to extract the information from video, audio, texts. Then, aggregate this information to segment and tag the video. There are two end-to-end tasks: Segmentation and Tagging, and the technology architecture is following:
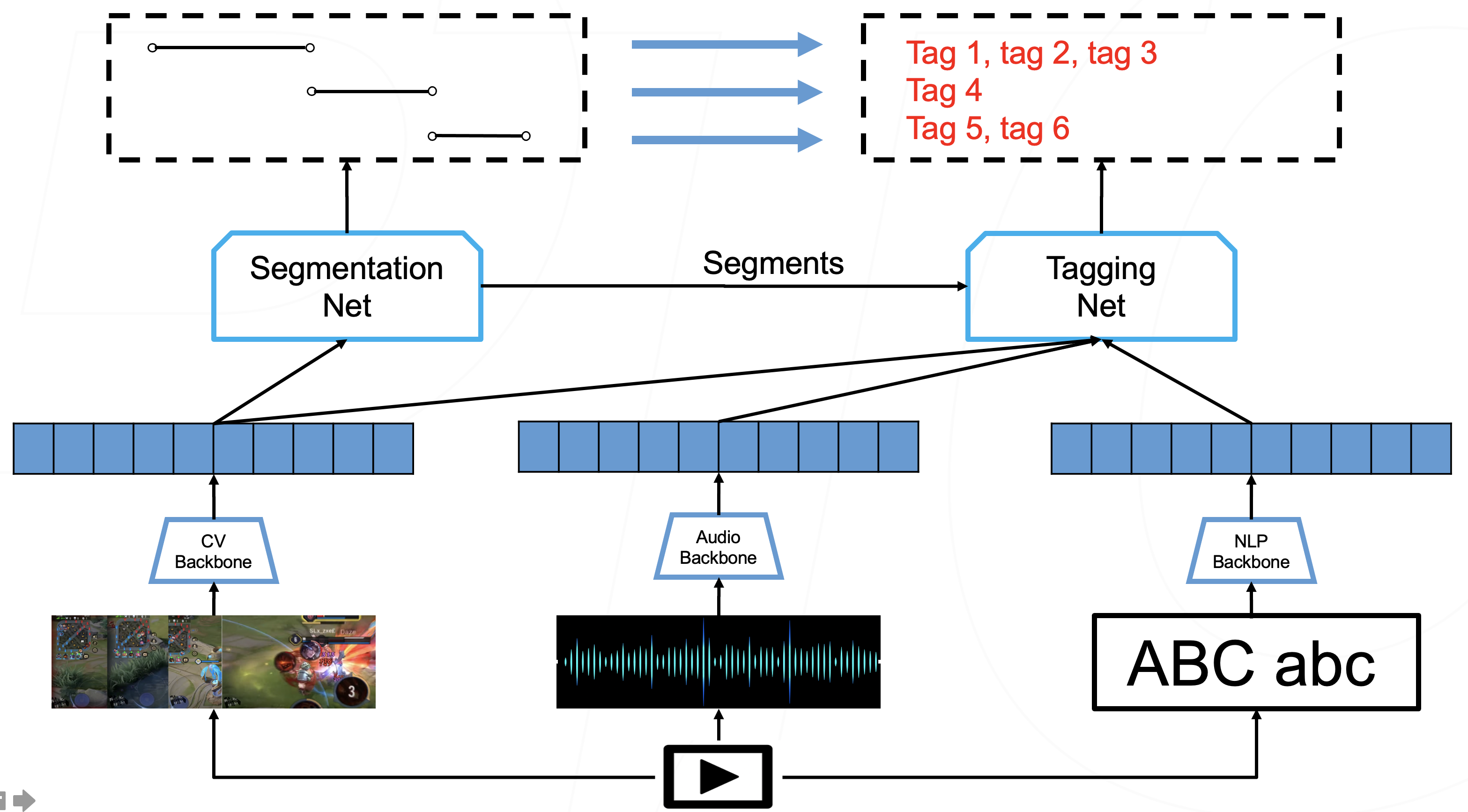
It uses three main deep learning models to process videos, audio, and text and extracts features. Then, the segmentation net takes the video features and identifies each segment point, just like a classifier does. Finally, the tagging net classifies tags in each segment, a standard multi-labels classifying process. The following list is the main algorithms that we have used or will try in the future.
- CV Backbone: Res-Net, Efficient Net, Botong(in-house)
- Audio Backbone: VGGish
- NLP Backbone: BERT, Transformer
- Segmentation Net: TCN,LGSS,RepNet,TransNet, unet ++, BMN
- Tagging Net: Swin, Clip Transformer, VIT
As you can see, the architecture is simple, but there are so many models that we can composite to enhance the model performance. There are so many details, both at the algorithm and engineer levels, which I ignore to present the whole picture in the limited space.
OK, that is all, hoping you enjoy it!
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!