A gift from Teacher-Student doesn't work for us
I have read a paper A Gift from Knowledge Distillation, published on CVPR at 2017, which has been cited for 690 plus since then, hoping that I could found a solution to the annotations shortage.
The main idea is that a smaller student DNN model imitates the flow between layers of the teacher DNN as following. As a result, the student can build some shortcuts from input matrices to output matrices, that is the student knows what it is, but not why.
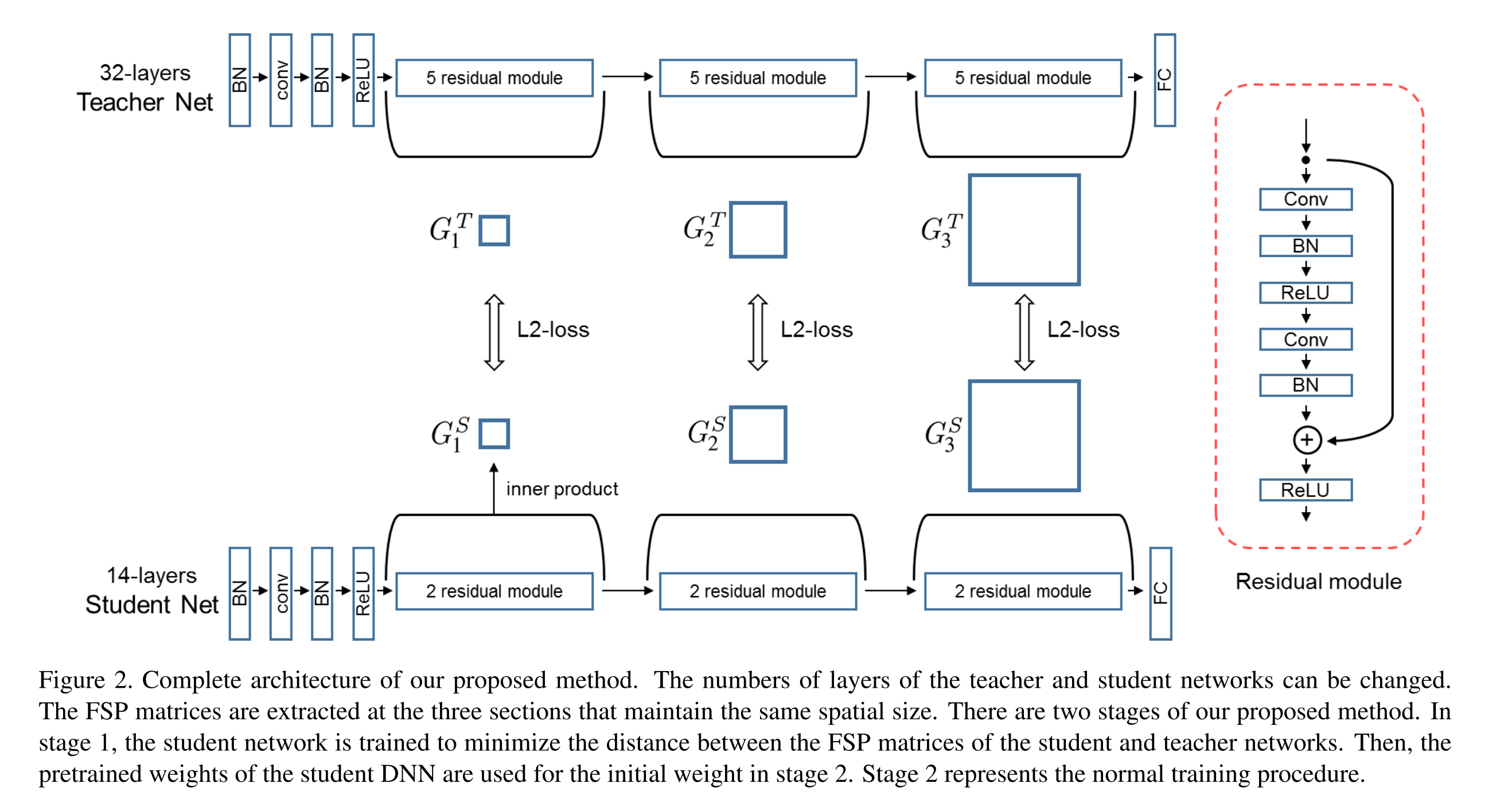
The teacher model can be a very deep model, and it’s the ResNet in this paper. Once the student has learned the flow, which is called FSP Matrices, it can be fine-tuning in your specific tasks. However, the student cannot reach the same level accuracy as the teacher does in transfer learning task as following.
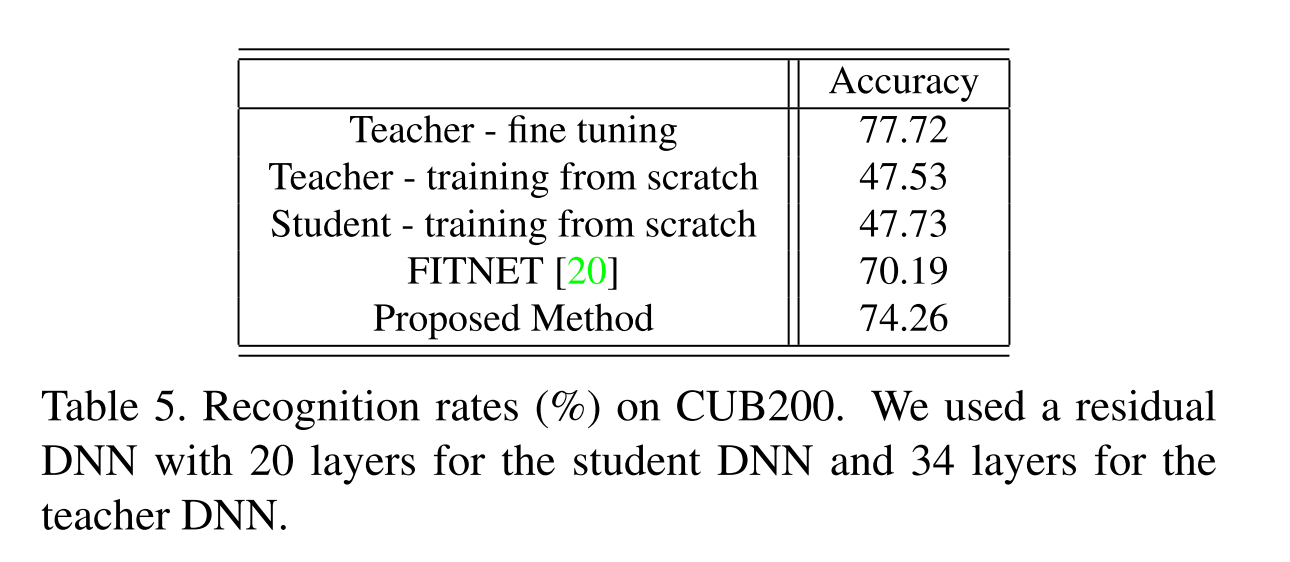
In our use case, we can still use a teacher model, we call it backbone, and fine tuning in the limited annotations. So, the benefits mentioned in this paper, which are training faster, smaller model and a slightly lift compared with the origin task, do not work for us.
The reason I read this paper is that a job candidate mentioned it in an interview with me recently. She said it can solve the annotation shortage problem. In her case, model compression should be considered as they provides to-Client services, but not in our case. Although I am slightly disappointed about the result, but I still feel happy to learn something new about model distillation.
Curiosity leads to progress.
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
您的打赏是对我最大的鼓励!